Welcome to RIBOBASE
RIBOBASE is an innovative database designed to facilitate easy access to transcriptomes and translatomes of various prokaryotes studied in the framework of the DFG Priority Programme 2002 'Small Proteins in Prokaryotes, an Unexplored World' (1). Our research focuses on ribosomally synthesized small proteins, which are proteins of ≤70 amino acids that are translated from small open reading frames (sORFs). These small proteins have diverse cellular functions, such as energy generation, transport, virulence, and symbiosis, as indicated by an increasing number of reports (2-4).
We have utilized NGS-based Ribosome profiling (Ribo-seq) to generate translatome maps and achieve an accurate census and precise annotation of proteins and small proteins (5-6) in different prokaryotes. Moreover, as prokaryotic genomes are densely packed, we also included for some organisms chemicals during the Ribo-seq procedure in order to map precisely both translation initiation and termination sites using TIS/TTS profiling (7-9). These allowed the accurate mapping of ORFs, including sORFs or alternative ORFs (alt-ORFs) within larger genes and revealed sORFs that overlap in frame with other ORFs and might therefore produce some of the same tryptic peptides, making them indistinguishable by mass spectrometry (10).
We hope the generated datasets will help to refine the translatome and uncover hidden ORFs/sORFs in various species. We will continuously update RIBOBASE with new datasets and welcome feedback from the scientific community. Our hope is that RIBOBASE will assist the prokaryotic scientific community in identifying relevant ORFs/sORFs, which could help in the understanding of the functioning of model organisms, such as pathogenic bacteria or prokaryotes of biotechnological interest, and ultimately lead to the design of therapeutic or biotechnological actions.
Technical Details
RIBOBASE provides a JBrowse2 (11) genome browser instance for each prokaryote covered in the framework of the DFG-SPP2002 program and other collaborations.
The generated Ribo-seq datasets have been processed using the HRIBO pipeline (12) and compiled into genome browser tracks, offering easy access for a specific group (private) or the whole scientific community (open access).
Private datasets are currently password protected and will become available to the community as soon as the data has been published.
JBrowse2 (11) is a modular online genome browser that allows to visualize and explore biological data.
JBrowse2 is still actively being developed and new features become available regularly.
For a nice overview on what features are currently available, please check out their webpage. They offer a gallery with pictures and many live demos.
Open Access Area
Campylobacter jejuni
The food-borne pathogen Campylobacter jejuni is a microaerophilic Epsilonproteobacterium and currently the leading cause of bacterial gastroenteritis worldwide. Because its annotated genome lacks homologs of key virulence factors used by other enteric pathogens, little is known about how it causes disease. In its small genome of ~1.6 Mbp, 54 small proteins of less than 70 aa are annotated. So far almost nothing is known about their involvement in C. jejuni physiology and verification of translation is lacking for most of them. Furthermore, the C. jejuni small proteome is likely larger than what is currently annotated.
The lab of Prof. Dr. Cynthia Sharma (University of Würzburg, Germany) has applied an integrative translatomics approach to map the coding capacity of this major human pathogen.
Escherichia coli str. K-12 substr. MG1655
This dataset section contains Ribo-Seq data for Escherichia coli, a Gram-negative facultative anaerobic bacterium. These datasets were generated in collaboration with Prof. Kirsten Jung's group from Ludwig-Maximilians-Universität (LMU) of Munich, Germany.
The Ribo-Seq datasets were prepared from wild-type E. coli K-12 substr. MG1655, grown aerobically at 37℃ in LB medium (pH 7.6),
and harvested during the exponential growth phase (OD600nm 0.5). Acid stress was subsequently induced by altering the pH of the cultures from 7.6 to 5.8, or 4.4 for 30 minutes before harvesting the samples.
These datasets offer a unique opportunity for researchers to explore gene expression and translation under acid stress conditions.
The original work can be found at: https://doi.org/10.1128/msystems.01037-23
Haloferax volcanii str. H119
We are excited to present our Ribo-seq datasets for the halophilic archaeon Haloferax volcanii, generated in collaboration with Prof. Anita Marchfelder from Ulm University, Germany. H. volcanii is a model organism for studying the unique adaptations of extremophiles to high-salt environments. Despite its importance, the translation of small open reading frames (sORFs) and their encoded proteins in H. volcanii remains poorly understood.
To address this knowledge gap, we established a Ribo-seq procedure for the wild-type H. volcanii H119 under standard growth conditions. Our datasets were generated at 45℃ in YPC medium during the exponential growth phase (OD600nm 0.4). Using computational tools and manual curation, we identified several novel sORFs in the H. volcanii genome.
Our Ribo-seq datasets offer a unique opportunity to explore the translation of protein and small proteins in this important model organism.
We believe that our datasets will be a valuable resource for the scientific community studying extremophiles and will advance our understanding of the biology of H. volcanii.
The original work can be found at: https://doi.org/10.1093/femsml/uqad001.
Mycobacterium tuberculosis H37Rv
This dataset section presents Ribo-seq data for Mycobacterium tuberculosis (Wade et al.), essential for understanding tuberculosis pathology.
The study provides a comprehensive analysis of open reading frames, revealing numerous previously unknown ORFs, primarily short in length. These findings offer valuable insights into the extensive translation occurring within the M. tuberculosis transcriptome, contributing significantly to the field of tuberculosis research.
The original work can be found at: https://doi.org/10.7554/eLife.73980.

Salmonella Typhimurium SL1344
This section contains Ribo-seq datasets for the pathogenic bacterium Salmonella Typhimurium, generated in collaboration with Prof. Jörg Vogel from the University of Würzburg, Germany. Ribo-seq datasets were prepared for the wild-type Salmonella Typhimurium grown in rich medium (LB), SPI-1, and SPI-2-inducing conditions.
The original work can be found at: 10.1093/femsml/uqaa002.
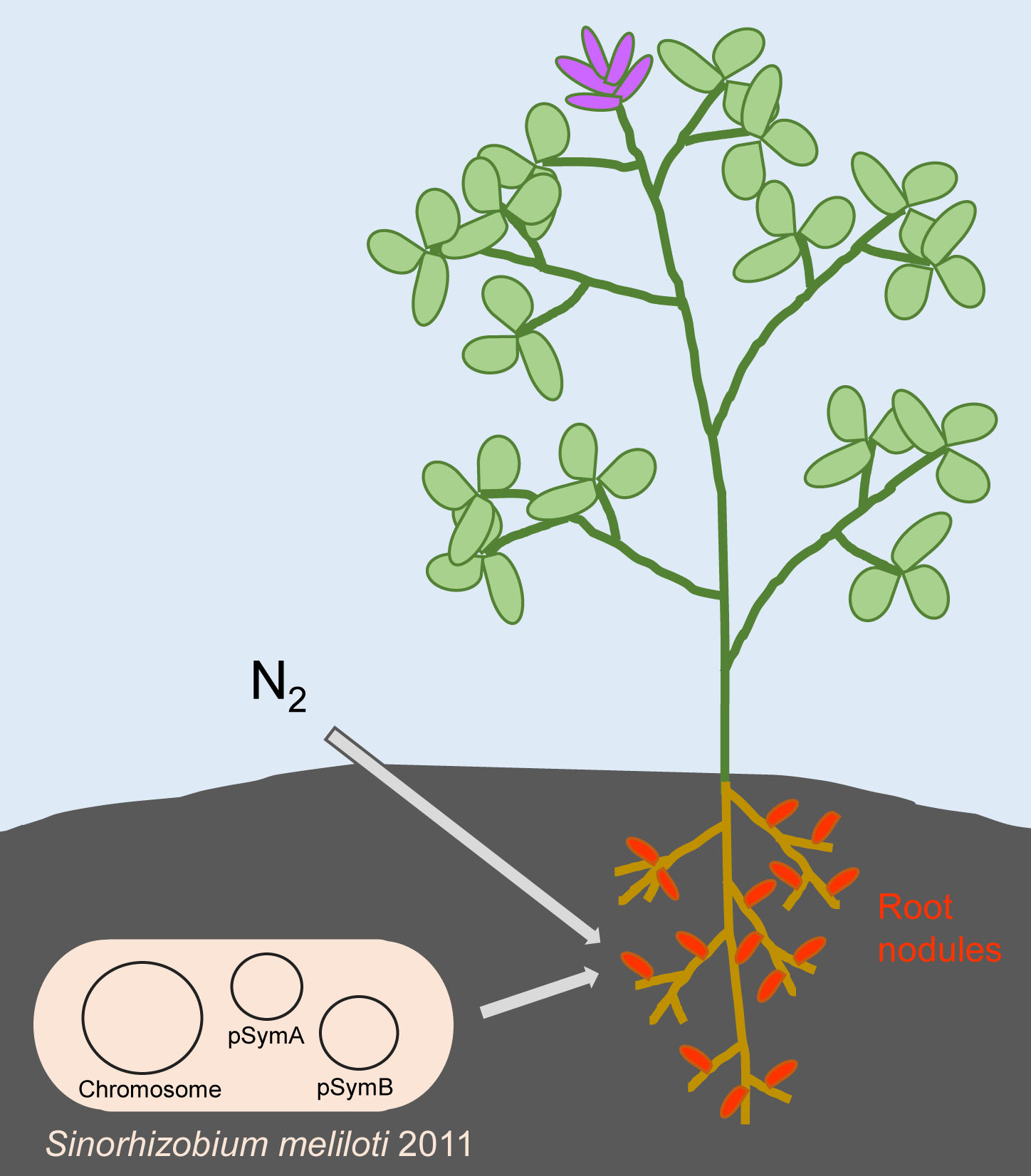
Sinorhizobium meliloti 2011
Exciting news for the scientific community interested in plant-symbiont interactions! We are thrilled to share our latest Ribo-seq datasets for Sinorhizobium meliloti, a key player in nitrogen fixation and an important partner of leguminous plants. These datasets were generated in collaboration with Prof. Elena Evguenieva-Hackenberg from the University of Giessen, Germany, and offer a unique opportunity to explore the translational landscape of this fascinating microbe.
These Ribo-seq datasets were prepared for the wild-type S. meliloti 2011 strain grown semi-aerobically at 30℃ in GMS minimal medium containing streptomycin and harvested in exponential growth phase (OD600nm 0.5).
With these datasets, you'll be able to dive deep into the translatome of S. meliloti and gain unprecedented insights into its overlooked small proteome.
The original work can be found at: https://doi.org/10.1093/femsml/uqad012 .
Private Area
Organisms in the private area are only accessible to the owners of the data and collaborators that received the login credentials.
These JBrowse instances become available to the community after the data has been published.
Escherichia Coli CFT073 (UPEC)
Under Construction

Methanosarcina mazei
This section showcases a valuable resource for the scientific community, providing access to high-quality Ribo-seq datasets for Methanosarcina mazei, a mesophilic methanogenic archaeon. These datasets were generated in collaboration with Prof. Ruth Schmitz-Streit from Kiel University, Germany. The Ribo-seq datasets are derived from wild-type Methanosarcina mazei strain Gö1, cultivated under both nitrogen-sufficient (Nitrogen+) and nitrogen-limited (Nitrogen-) conditions, and harvested during the exponential growth phase (OD600nm 0.3-0.4). These datasets represent a significant contribution to the field and will undoubtedly facilitate further insights into the molecular mechanisms underlying the growth and adaptation of this unique organism.
Synechocystis sp. (for review)
This section offers a valuable resource to the scientific community, providing access to Ribo-seq and TIS/TTS profiling datasets for Synechocystis, a widely studied cyanobacterium. The datasets were produced in collaboration with Prof. Wolfgang Hess from the University of Freiburg, Germany. The Ribo-seq datasets were generated from wild-type Synechocystis 6803 cultivated under various growth conditions (High carbon, low carbon, nitrogen limitation, and dark), and harvested during the exponential growth phase (OD600nm 0.4). TIS/TTS profiling datasets were obtained from wild-type Synechocystis 6803 cultivated under standard growth conditions and harvested during the exponential growth phase (OD600nm 0.4).
These datasets represent a significant contribution to the field, enabling researchers to explore the molecular mechanisms underlying Synechocystis's adaptation to different growth environments. By offering unprecedented insights into gene annotation and translation, these datasets will help drive the development of novel strategies for enhancing the performance of cyanobacteria for biotechnological applications.
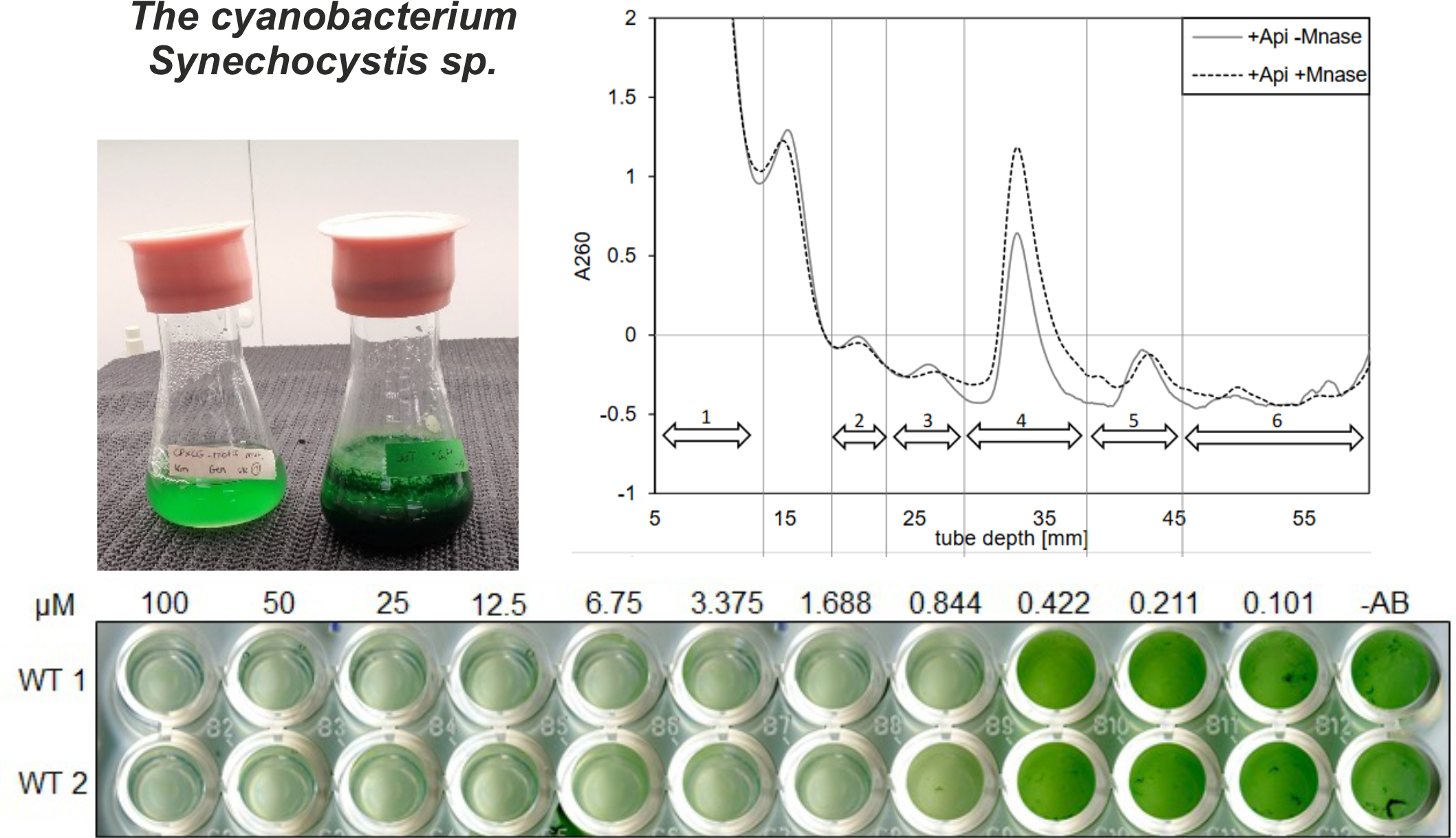
Synechocystis sp.
This section offers a valuable resource to the scientific community, providing access to Ribo-seq and TIS/TTS profiling datasets for Synechocystis, a widely studied cyanobacterium. The datasets were produced in collaboration with Prof. Wolfgang Hess from the University of Freiburg, Germany. The Ribo-seq datasets were generated from wild-type Synechocystis 6803 cultivated under various growth conditions (High carbon, low carbon, nitrogen limitation, and dark), and harvested during the exponential growth phase (OD600nm 0.4). TIS/TTS profiling datasets were obtained from wild-type Synechocystis 6803 cultivated under standard growth conditions and harvested during the exponential growth phase (OD600nm 0.4).
These datasets represent a significant contribution to the field, enabling researchers to explore the molecular mechanisms underlying Synechocystis's adaptation to different growth environments. By offering unprecedented insights into gene annotation and translation, these datasets will help drive the development of novel strategies for enhancing the performance of cyanobacteria for biotechnological applications.
Acknowledgements
RIBOBASE is developed by members of the Z2 project of the DFG funded SPP2002 - Small Proteins in prokaryotes, an Unexplored World.
RIBOBASE is hosted on a server provided by the Backofen Group at the university of Freiburg.
Z2 project SPP2002
Small Proteins in prokaryotes, an Unexplored World

AG Sharma
- Prof. Cynthia Sharma
- Dr. Sarah Svensson
- Dr. Lydia Hadjeras

AG Backofen
- Prof. Rolf Backofen
- Rick Gelhausen

We want to thank all the members and organizers of the SPP2002 and all the contributors to the RIBOBASE.
Acknowledgements for the individual contributors are available for each sub-project.
References
Data Publications
-
Schumacher K, Gelhausen R, Kion-Crosby W, Barquist L, Backofen R, Jung K 2023.
Ribosome profiling reveals the fine-tuned response of Escherichia coli to mild and severe acid stress. bioRxiv 2023.06.02.543275;
https://doi.org/10.1101/2023.06.02.543275 -
Froschauer K, Svensson SL, Gelhausen R, Fiore E, Kible P, Klaude A, Kucklick M, Fuchs S, Eggenhofer F, Engelmann S, Backofen R, Sharma CM 2022.
Complementary Ribo-seq approaches map the translatome and provide a small protein census in the foodborne pathogen Campylobacter jejuni. bioRxiv 2022.11.09.515450;
https://doi.org/10.1101/2022.11.09.515450 -
Hadjeras L, Heiniger B, Maaß S, Scheuer R, Gelhausen R, Azarderakhsh S, Barth-Weber S, Backofen R, Becher D, Ahrens CH, Sharma CM, Evguenieva-Hackenberg E. 2023.
Unraveling the small proteome of the plant symbiont Sinorhizobium meliloti by ribosome profiling and proteogenomics. microLife, uqad012,
https://doi.org/10.1093/femsml/uqad012 -
Hadjeras L, Bartel J. Maier LK, Maaß S, Vogel V, Svensson SL, Eggenhofer F, Gelhausen R, Müller T, Alkhnbashi OS, Backofen R, Becher D, Sharma CM, Marchfelder A. 2023.
Revealing the small proteome of Haloferax volcanii by combining ribosome profiling and small-protein optimized mass spectrometry. microLife, Volume 4, 2023, uqad001,
https://doi.org/10.1093/femsml/uqad001 -
Venturini E, Svensson SL, Maaß S, Gelhausen R, Eggenhofer F, Li L, Cain AK, Parkhill J, Becher D, Backofen R, et al. 2020.
A global data-driven census of Salmonella small proteins and their potential functions in bacterial virulence. microLife.
https://doi.org/10.1093/femsml/uqaa002 - Gelhausen R, Müller T, Svensson SL, Alkhnbashi OS, Sharma CM, Eggenhofer F, Backofen R, 2022.
RiboReport - benchmarking tools for ribosome profiling-based identification of open reading frames in bacteria, Briefings in Bioinformatics, Volume 23, Issue 2, March 2022, bbab549,
https://doi.org/10.1093/bib/bbab549 - Gelhausen R, Svensson SL, Froschauer K, Heyl F, Hadjeras L, Sharma CM, Eggenhofer F, Backofen R. 2021. HRIBO: high-throughput analysis of bacterial ribosome profiling data. Bioinformatics 37: 2061–2063.
https://doi.org/10.1093/bioinformatics/btaa959
General References
- https://www.spp2002.uni-kiel.de/wordpress/
- Storz G, Wolf YI, Ramamurthi KS. 2014. Small proteins can no longer be ignored. Annu Rev Biochem 83: 753–777.
https://doi.org/10.1146/annurev-biochem-070611-102400 - Hemm MR, Weaver J, Storz G. 2020. Escherichia coli Small Proteome. Ecosal Plus 9.
https://doi.org/10.1128/ecosalplus.esp-0031-2019 - Duval M, Cossart P. 2017. Small bacterial and phagic proteins: an updated view on a rapidly moving field. Curr Opin Microbiol 39: 81–88.
https://doi.org/10.1016/j.mib.2017.09.010 - Ingolia NT, Brar GA, Rouskin S, McGeachy AM, Weissman JS. 2012. The ribosome profiling strategy for monitoring translation in vivo by deep sequencing of ribosome-protected mRNA fragments. Nat Protoc 7: 1534–1550.
https://doi.org/10.1038/nprot.2012.086 - Vázquez-Laslop N, Sharma CM, Mankin A, Buskirk AR. 2022. Identifying Small Open Reading Frames in Prokaryotes with Ribosome Profiling. J Bacteriol 204: e0029421.
https://doi.org/10.1128/jb.00294-21 - Meydan S, Marks J, Klepacki D, Sharma V, Baranov PV, Firth AE, Margus T, Kefi A, Vázquez-Laslop N, Mankin AS. 2019. Retapamulin-Assisted Ribosome Profiling Reveals the Alternative Bacterial Proteome. Mol Cell 74: 481-493.e6.
https://doi.org/10.1016/j.molcel.2019.02.017 - Froschauer K, Svensson SL, Gelhausen R, Fiore E, Kible P, Klaude A, Kucklick M, Fuchs S, Eggenhofer F, Engelmann S, Backofen R, Sharma CM. 2022. Complementary Ribo-seq approaches map the translatome and provide a small protein census in the foodborne pathogen Campylobacter jejuni. bioRxiv.
https://www.biorxiv.org/content/10.1101/2022.11.09.515450v1 - Mangano K, Florin T, Shao X, Klepacki D, Chelysheva I, Ignatova Z, Gao Y, Mankin AS,Vázquez-Laslop N. 2020. Genome-wide effects of the antimicrobial peptide apidaecin on translation termination in bacteria. eLife 9.
https://doi.org/10.7554/eLife.62655 - Orr MW, Mao Y, Storz G, Qian S-B. 2020. Alternative ORFs and small ORFs: shedding light on the dark proteome. Nucleic Acids Res 48: 1029–1042.
https://doi.org/10.1093/nar/gkz734 - JBrowse 2: A modular genome browser with views of synteny and structural variation (2022). bioRxiv.
https://doi.org/10.1101/2022.07.28.501447 - Gelhausen R, Svensson SL, Froschauer K, Heyl F, Hadjeras L, Sharma CM, Eggenhofer F, Backofen R. 2021. HRIBO: high-throughput analysis of bacterial ribosome profiling data. Bioinformatics 37: 2061–2063.
https://doi.org/10.1093/bioinformatics/btaa959
Contact us
If you are interested in having your own data available in RIBOBASE, please Contact us.